Members:
AMD, blazer, gearjunkie, golem445, hops, meowmeowbean, s3inlc, waffle, winxp5421
usasoft (infra)
Introduction
A huge thanks to KoreLogic for once again hosting the annual premier password cracking contest. This year we finally saw the appearance of Argon2 hashes, along with other weird and wonderful algorithms such as saph512, RC2, gocrypt & broken SHA1s. Congratulations to HashMob for topping the scoreboard with 4.89 billion points coming first, with hashcat coming at their heels at 4.83 billion points, we came in at third with 2.65 billion points. It was refreshing to see a wild new team_vodka, which almost came third. Congratulations to the street team “ThatOnePasswordWas40Passwords” which topped the street scoreboard by having almost 7x the number of points compared to the second team. This year, there were a multitude of challenge files in addition to an initial drop of hashes to keep us on our toes throughout the whole 48-hour duration.
Hashes
SM3crypt/ saph512 / Azure
SM3crypt / saph512 modules were written very early into hashcat allowing us to compute these all on GPU. Some time was wasted re-implementing the Azure hashes, due to the format differences it took us some time to realize that the format was already created. Due to us having GPU implementations so early, we were able to crack the highest number of SM3crypt and saph512 compared to the other teams.
Broken SHA1
This was chopped up into smaller parts for matching in mdxfind which supports variable hash lengths and later re-assembled. The point to work ratio for these did not appear to be worthwhile, so these were deemed low priority.
Argon2
We found that if we removed the shiro prefix along with flipping the m and t variables, we were able to load these into john the ripper GPU to crack. It is also important to note that cyclone’s argon2 cracker works with these as well. A small but important gotcha is that cyclone’s cracker may not report the crack on some systems.We are unable to replicate this issue post contest (possible PEBKAK, apologies cyclone).
Radmin3
A bash script looping radmin3_to_hashcat.pl was created in a loop to parse the registry file into crack-able lines. We noticed this produced several faulty lines (did not have time to investigate these).
Challenges
Challenge 1
ARJ, a strange and bizarre archive format that most of us weren’t aware of. We tackled these using various tools, from Elcomsoft’s archive recovery tool to an ancient cracker which required someone to boot up a 32-bit Windows XP system to run. Other than spotting a UT8-pass in the list and tracing through each note file leading onto the next ARJ we did not see use for this archive. We tried to pair up the usernames with those from other known hashes, but were not able to correlate these. We tried pairing up the passwords of the ARJ with the passwords in the notes and different orders and tested these against the bcrypts as well. It appeared we wasted a considerable amount of time with these that didn’t really lead us anywhere.
Gocryptfs
A gocryptfs cracker was developed. However, we were not able to get any cracks for this challenge. We also had a member go down this rabbit hole only to later realize that the version used for CMIYC had patched the flaws found in the audit above.
Challenge 2
We were able to decrypt the pcap file and crack the password. We were then able to use the password to decode the data packets and reassemble the various data streams. This allowed us to intercept various communications including basic http/ftp and email communications from the tcp/ip streams. The communications look like this after reassembling.
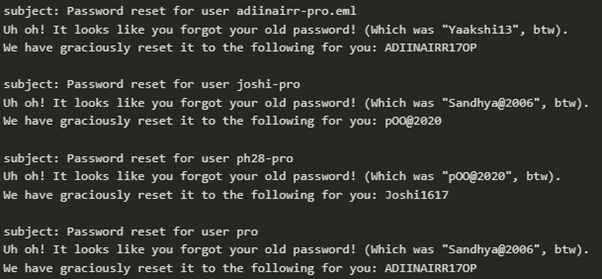
We were not able to make use of the decoded data.
Pybcryptk.py
We completely overlooked this file and did not make use of it to identify the underlying algorithm until quite late into the contest.
Challenge 3
While we were able to open the initial zip containing a multitude of more zips, we did not crack any.
Challenge 4
We created an RC2 cracker, but were not able to apply any hints or correlated data for this attack early on. We later made some solves using crcmatch.
Challenge 5
We were able to make use of the app.log success/failed attempts to assist us in making solves for various logins. Upon closer inspection of the log file, there was a CRC checksum for the successful logins. Through trial and error, we were able to identify the correct CRC algorithm used (CRC8). This hint provided also gave us the partial mask to a subset of hashes and looked like the image below.
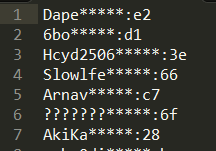
Knowing the CRC8 checksum meant that we could now speed up the cracking for each of the logins from the log file by up to 256 times. Even with a mask and checksum meant that brute forcing the unknown portion would still take considerable time to cover a ?a?a?a?a mask for the slow bcrypt/argon algorithms.
A new tool was created called crcmatch, this tool would accept an input, use the half mask input as a secondary list and output the full plain if the CRC matched. It was at this time, roughly 2 hours before the end of the contest that the obscure bcrypt $2b$ algorithm was identified via a go implementation (bcrypt base64(hmac sha256 (salt)). This was quickly reversed engineered and implemented into mdxfind. With around 1.5 left we were able to perform a “likely brute force” of the suffix. This involved extracting and or generating a set of mask suffixes which we believed would have a high probability of being successful. Examples would include 19?d?d?s, 202?d?s and ?l?l?l?l?s. We were able to pipe the output of crcmatch | mdxfind which allowed us to solve the highest number of bcr256 hashes.
Right after the contest ended we also figured the algorithm for the other elusive bkr256 $2y$ hashes being bcrypt with truncated salt, password HMAC-SHA256 with the untruncated salt as the key. The salt can have only 1 of 4 possible values. A build of mdxfind was created which cycles through all 4, rebuilds salt, and tries 4 different salts for each plaintext.
Patterns
We largely based our attacks using data extracted from various RFC resources namely RFC 1000, 1002, 1008, 1077 & 1096 as these appeared to produce consistent founds across almost all the hash lists. Some samples for the Azure hash list shown below, we found that replacing a space character with a symbol for 2,3,4 word combinations yielded founds.

Similarly, the above pattern also worked on texts such as “Snowpiercer” and “Seven Samurai” which were the themes for this year’s DEF CON. While we noticed a “Star Trek” theme present, we did not spend much time pursuing this to identify the exact pattern. We largely used an internal version of PACK2 to generate n-grams from the various text excerpts listed above for our attacks.
What went wrong
While we had the compute resources, knowledge, developers and crackers present, we failed to see the solves through with the different challenges. It almost felt like we were inundated with challenges and new tasks, and before we could fully catch up, another challenge was dropped. We were unable to make meaningful correlations with the challenges which we had solved. We wasted too much time building tooling to solve new challenges, while at the same time trying to piece together the solved challenges. We did not extensively test the zip files and pay attention to warning messages, which hindered our ability to leverage the hints they provided.
Closing remarks
Like the famous Michelangelo once said "Ancora Imparo". Despite having competed for many years, our team is still learning something new every contest. While some of the challenges made things quite frustrating, it was overall a fun experience. If you are a like minded individual and want to contribute to our team, reach out.