
Bitcrack / Hashkiller 2016 contest write-up
Members
Amd
|
gearjunkie
|
mastercracker
|
usasoft
|
blazer
|
hops
|
Milzo
|
User
|
cvsi
|
Jimbas
|
s3in!c
|
Waffle
|
espira
|
jugganuts420
|
tony
|
winxp5421
|
Software
HashcatV3 & HashcatV2 (https://hashcat.net/), MDXfind (https://hashes.org/mdxfind.php), hashtopussy (fork of the hashtopus project), TeamLogic (hash management platform), Unified List Manager (http://unifiedlm.com/)
Hardware
GPU (GH)
|
CPU (cores)
|
CPU (cores) [bcrypt only]
|
Total (cores)
| |
Base
|
150 (SHA1)
|
100
|
130
|
230
|
Peak
|
190 (SHA1)
|
250
|
300
|
550
|
A constant combined compute power of 150 GH (measured on SHA1 bruteforce) was used throughout the contest. This figure peaked to about 190 GH which is the rough equivalent of 35 GTX 980Ti. Around 130 CPU cores were reserved solely for GPU unfriendly algorithms, this burst to maximum of 300 cores for a short period. An additional 100 CPU cores were used for all other algorithms which peaked to 250 cores.
Strategy
- Free-for-all approach
- Have fun
- Utilize resources efficiently
- Surprise the other teams
Before the contest
We redeveloped our hash management system and ensured it was fully functional prior to the contest. In addition we had the pleasure of beta testing a personal project of one of our members. An improved distributed hashcat system dubbed Hashtopussy, (a fork of the hashtopus project) with numerous improvements including; a revamped interface, multi-user and user-rights-management support, optimized hash handling and of course support for Hashcat3. Keep an eye out for this project, as it will be released soon.
Hashtopussy instances were deployed and allowed the team to remotely manage, voluntarily donate compute cycles and deploy tasks across clusters of compute nodes and streamline the cracking process. As hashcat is now open source (big thanks to the hashcat developers), we were able to easily apply minor changes to ensure it played nicely in a distributed environment.
During the contest
We started off by probing all algorithms looking, for any signs of patterns and tackled the bcrypts immediately by running extremely simple checks against common passwords. We recovered about 20 bcrypts within the first hour on our CPU cluster and were able to feed it with enough test candidates allowing us yield hits consistently.
MDXfind was used to quickly test algorithms which hashcat couldn’t initially handle namely DCC, with Waffle quickly adding WBB support. Once we knew these hashes were valid, support for both these algorithms were swiftly added to hashcat.
As there is already a write-up regarding the patterns for the generated hashes we won’t go into them, other than saying we spotted some and missed others and discovered some too late into the contest. 11 hours into the contest and we had hits for every algorithm except phpbb3_gen which we didn’t waste too much time pursuing. This was a pretty good starting point and kept us busy through the remainder of the time.
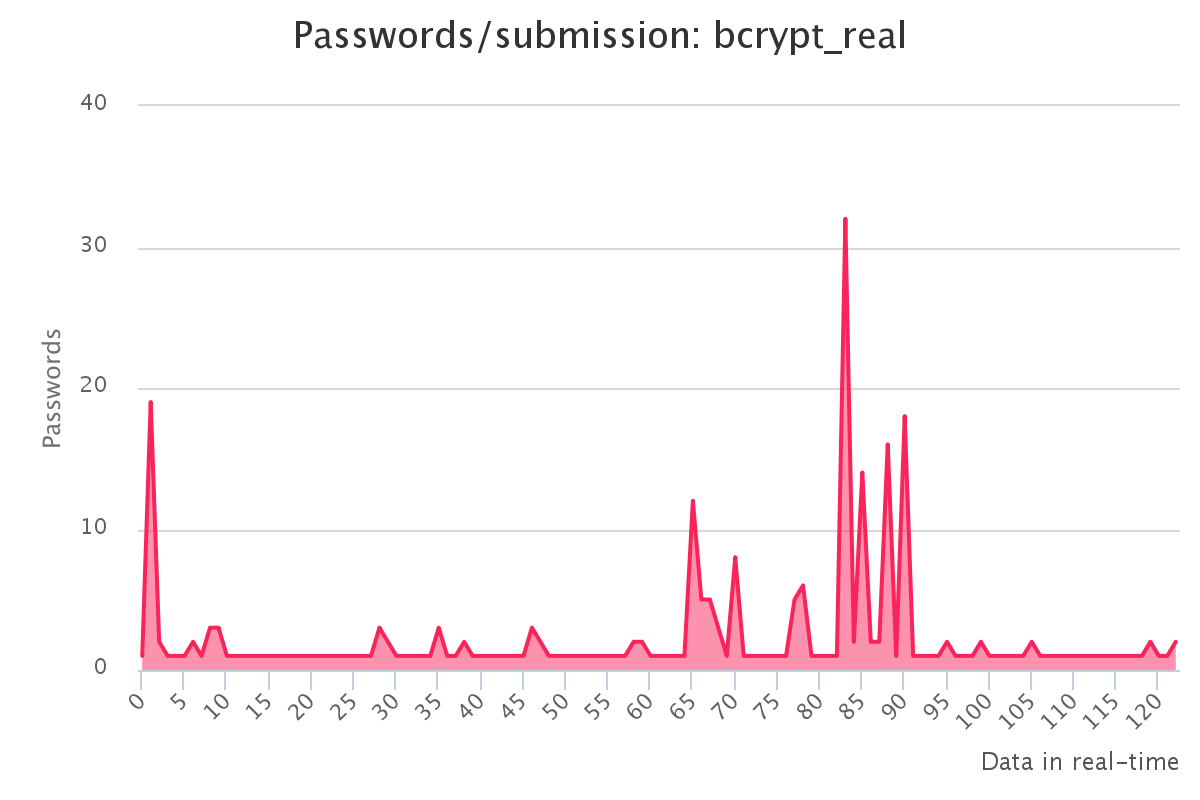
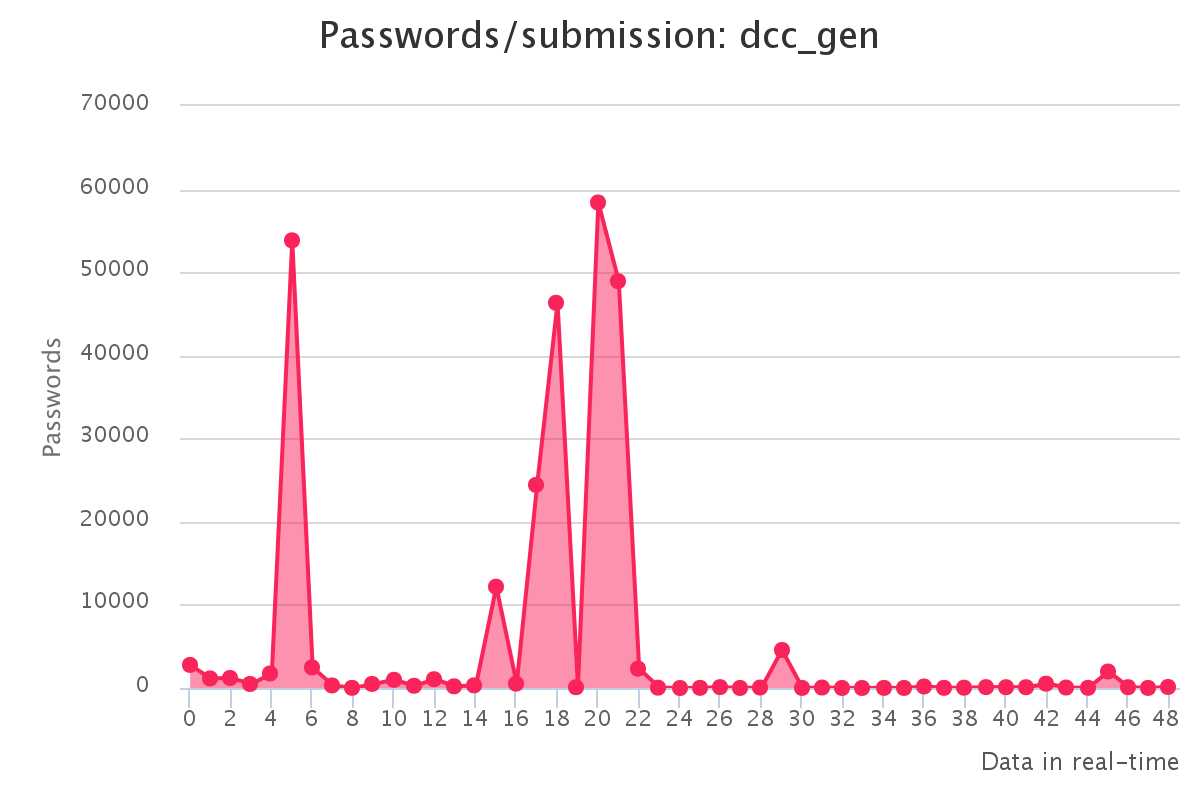
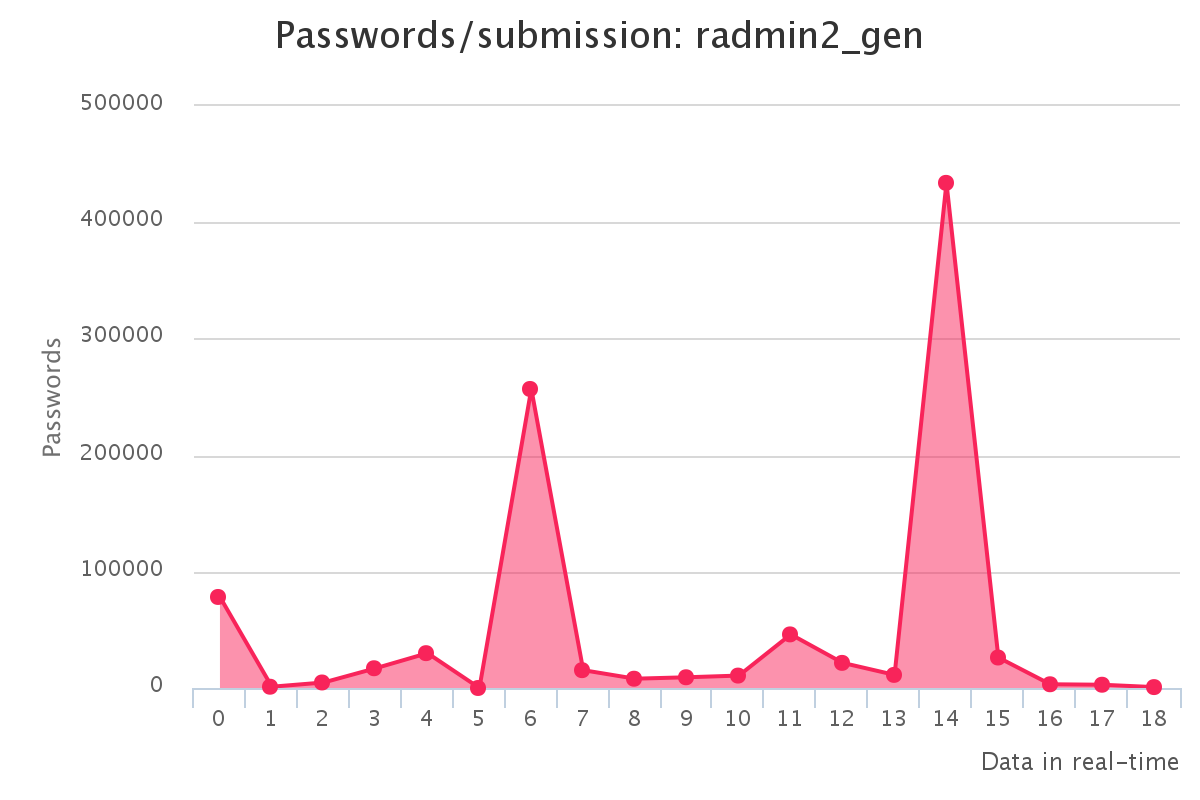
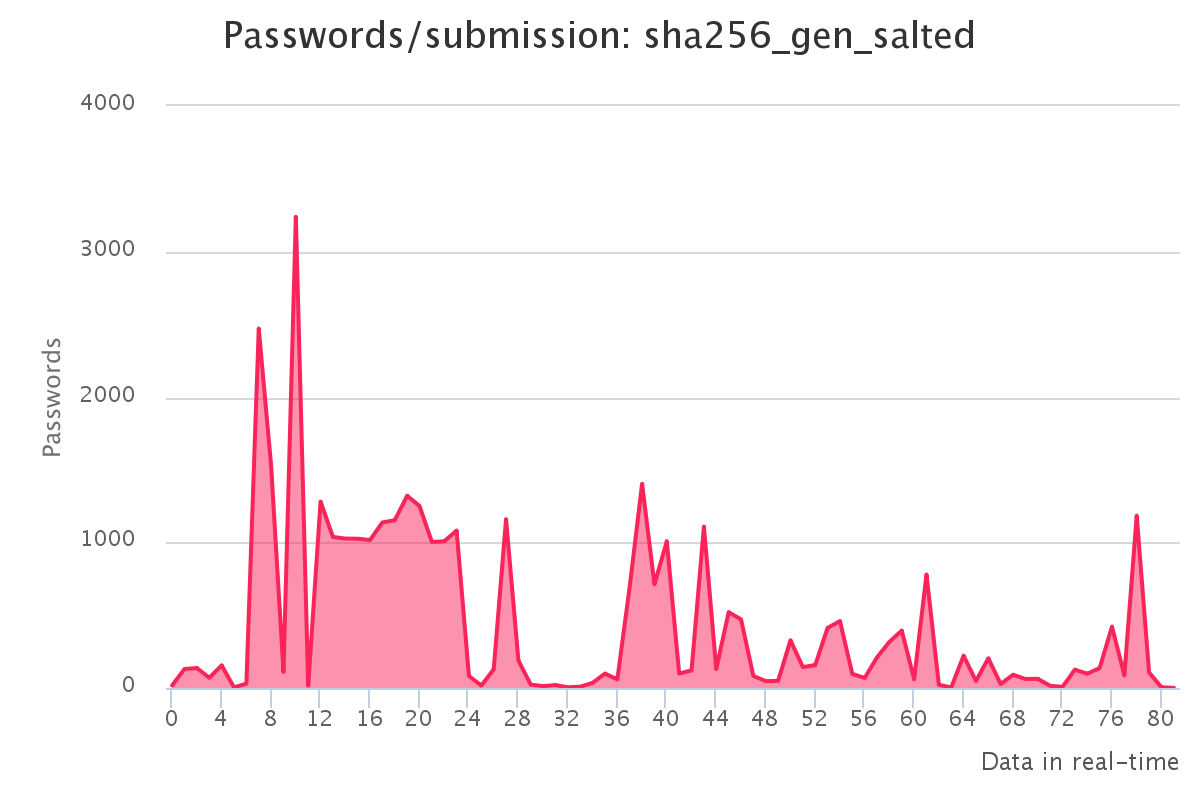
To make it up to some individuals who have complained that our large submission towards the end of the contest would have skewed any pretty graphs, we have decided to provide analytics gathered by our hash management system. The graphs should reflect the actual crack progression for each individual hashlist throughout the contest. This should provide some insight on how we tackled each hashlist.
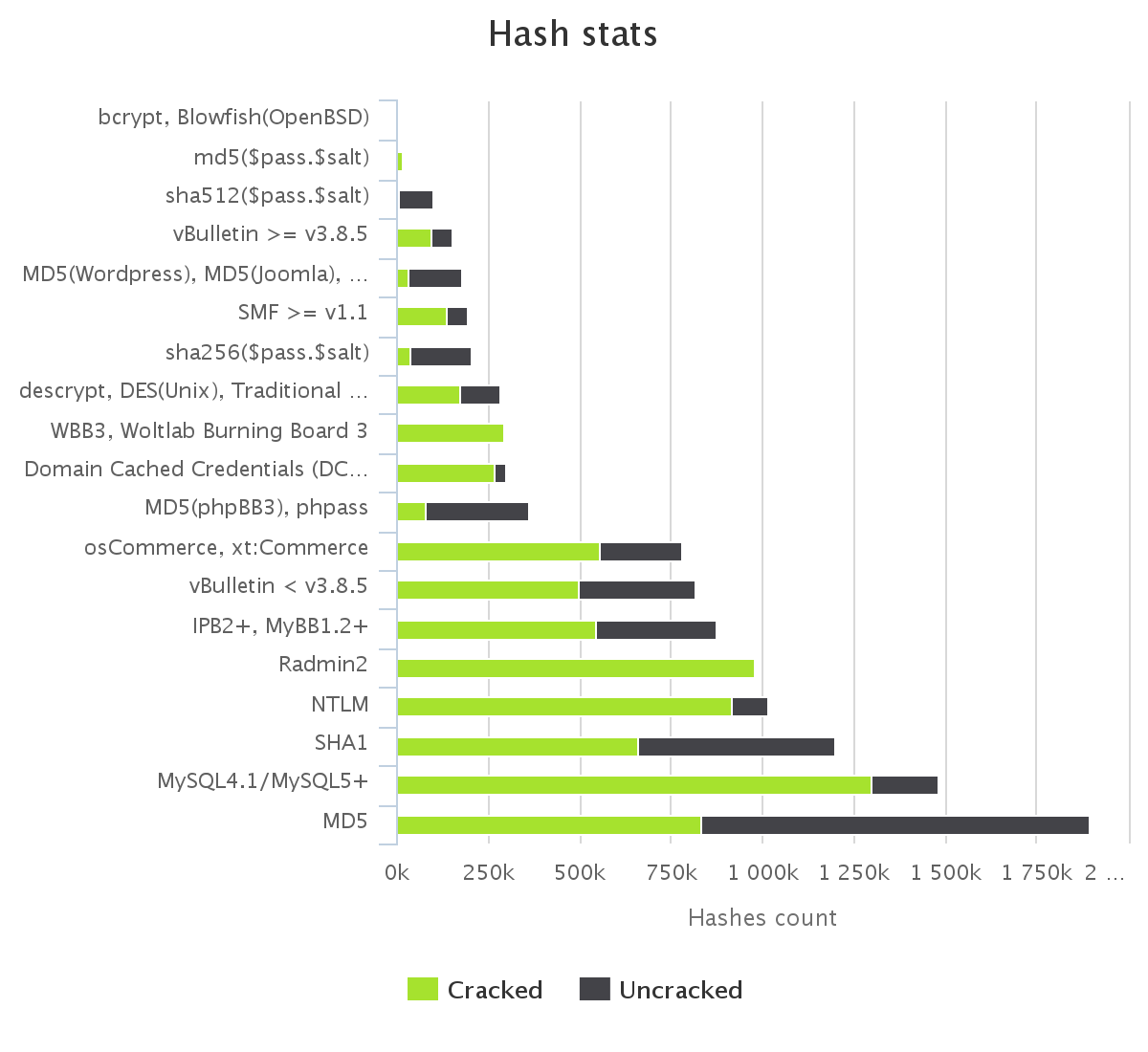
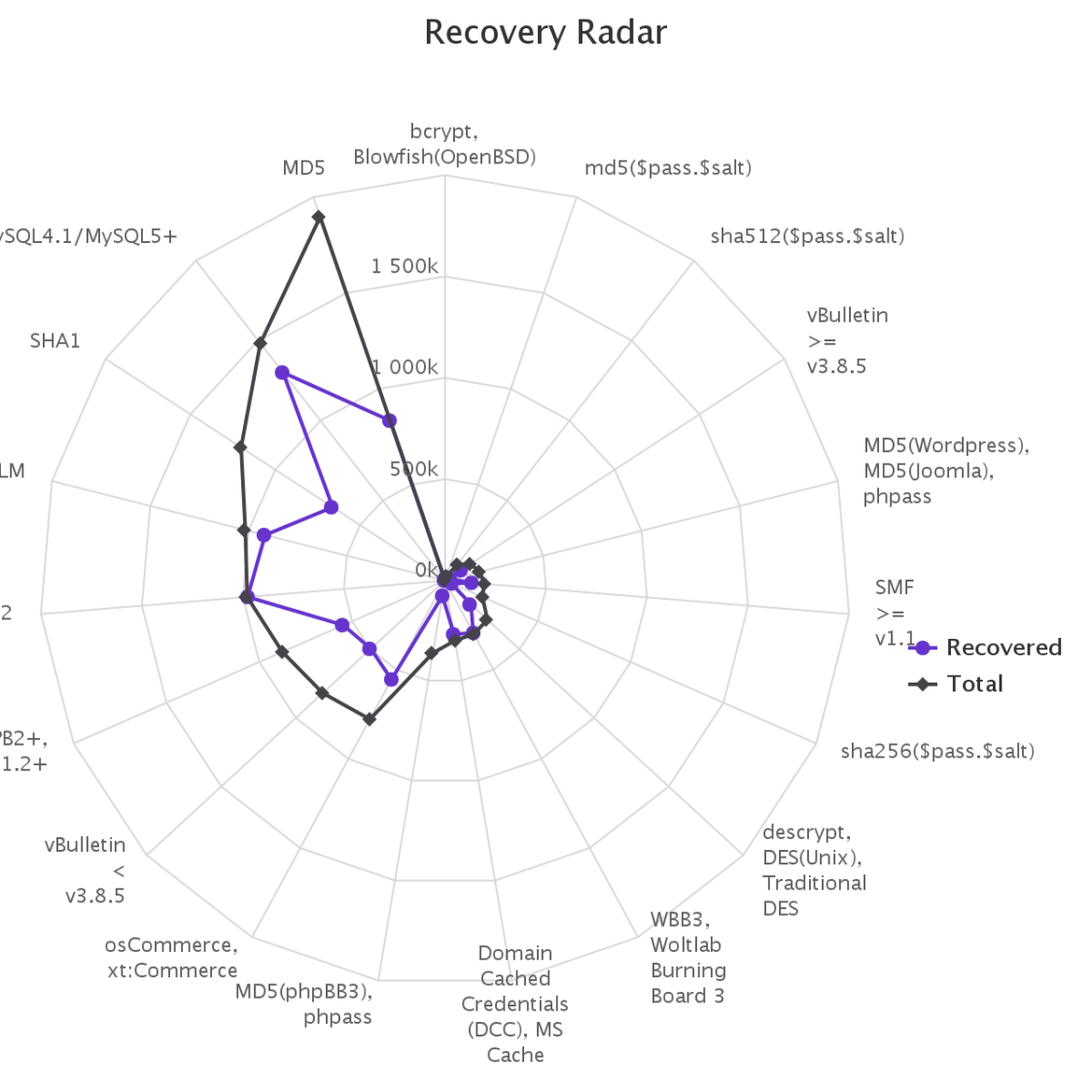
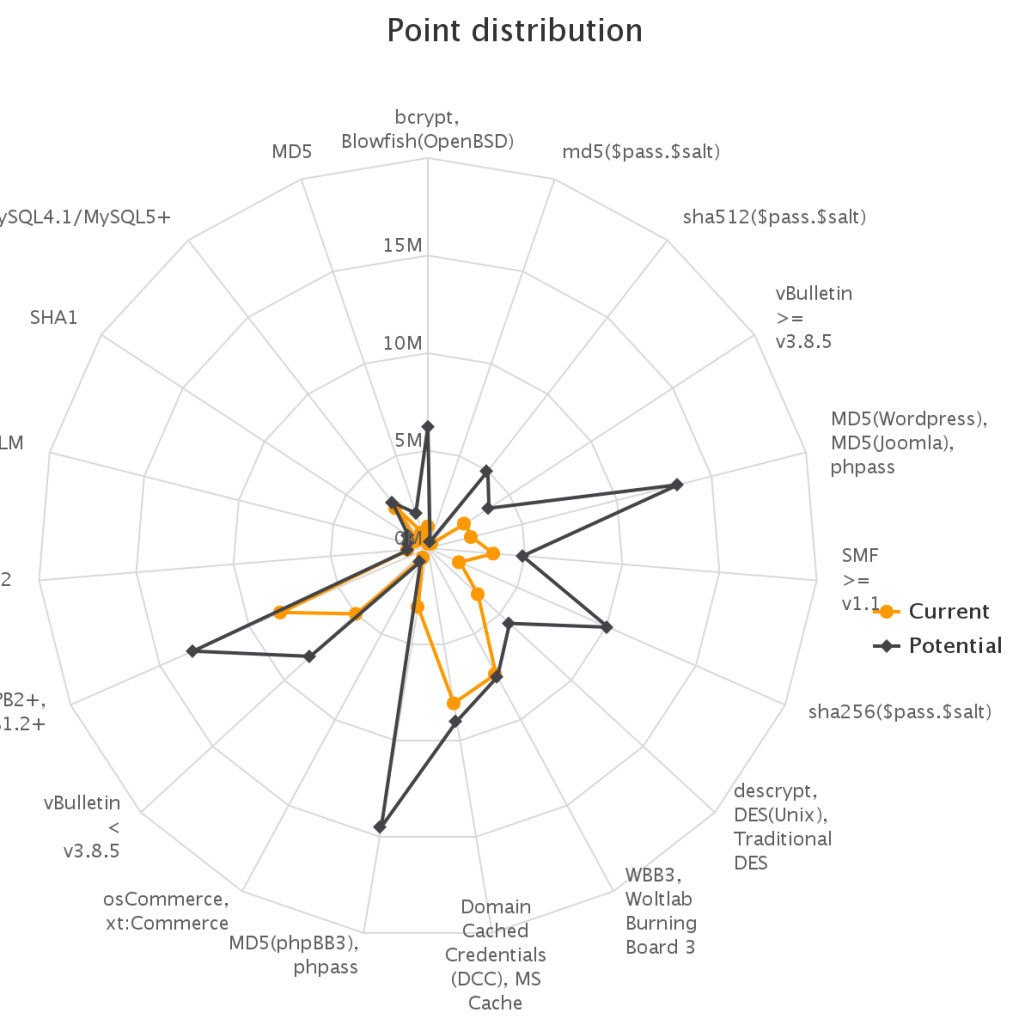
Graphs for real hashlists
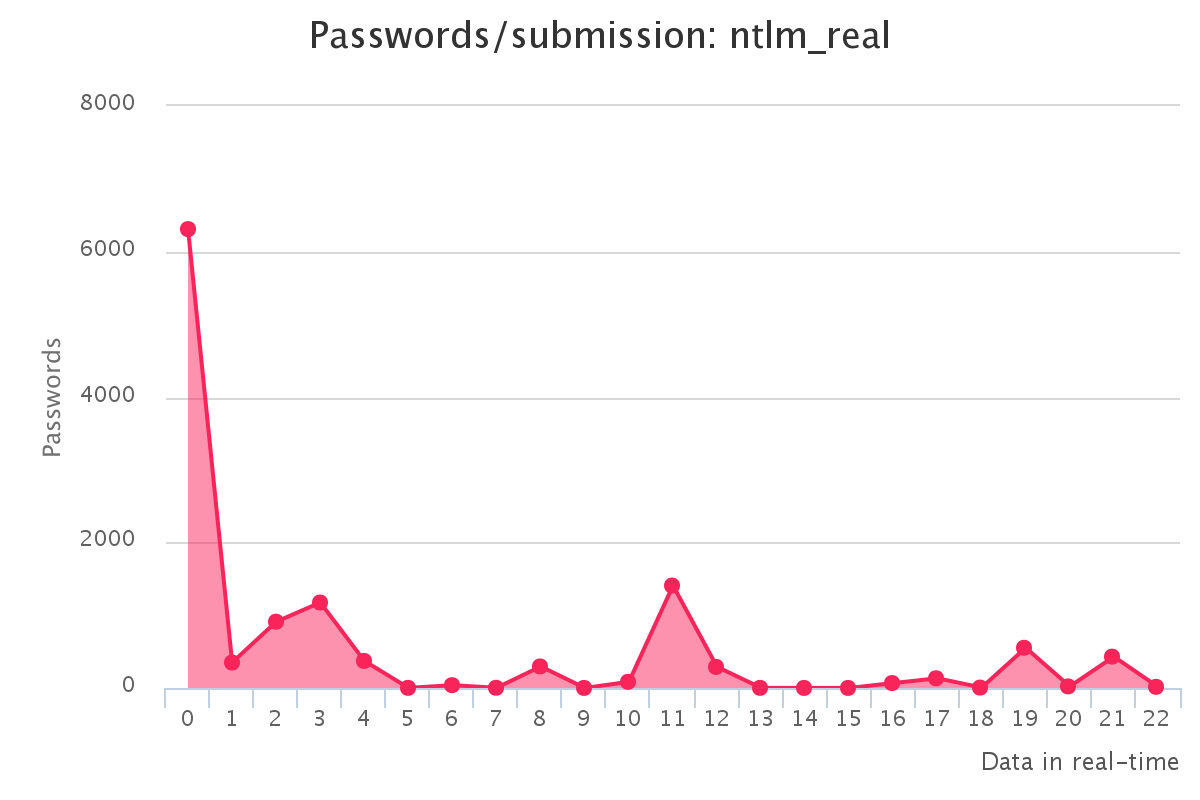
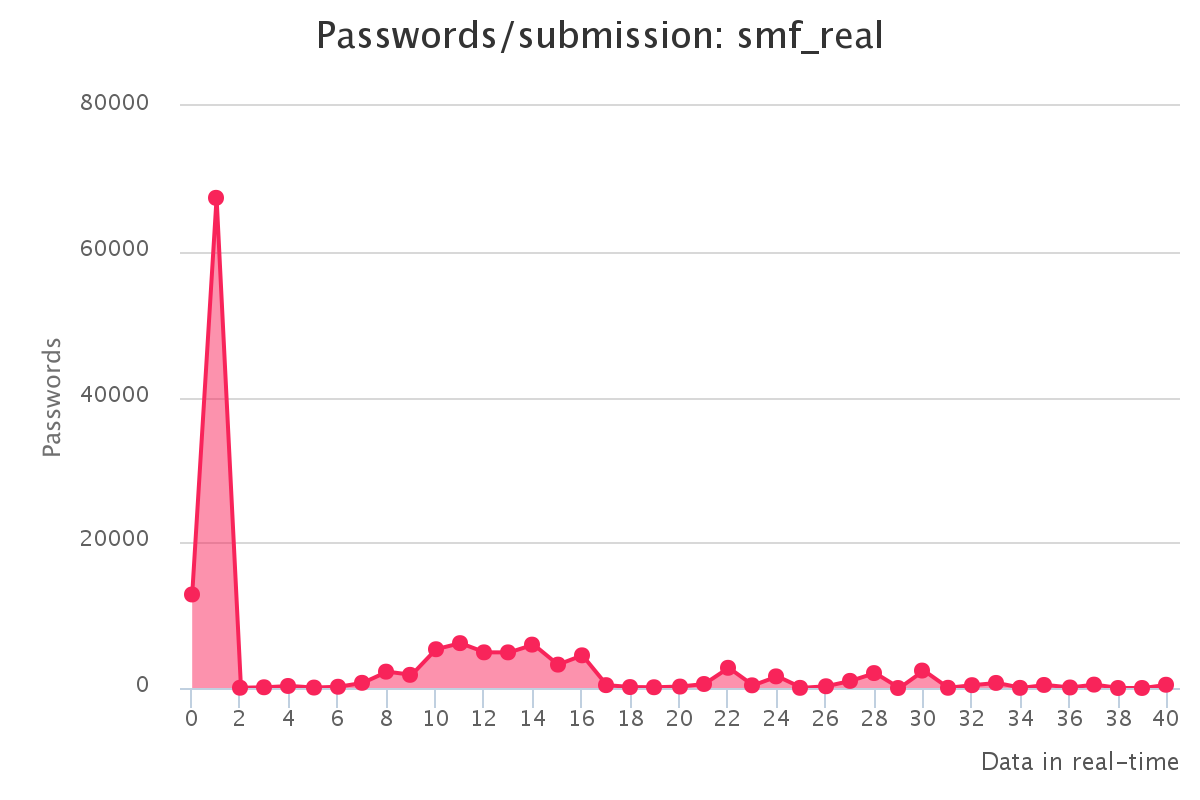
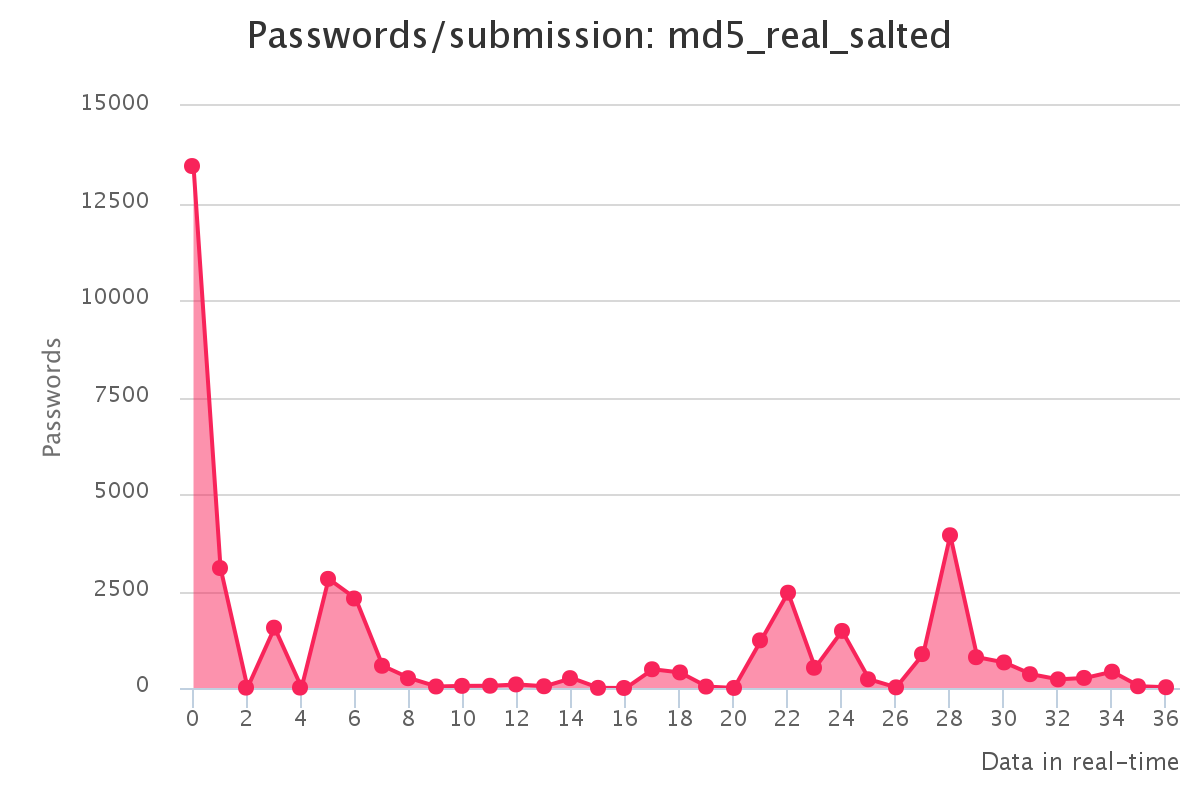
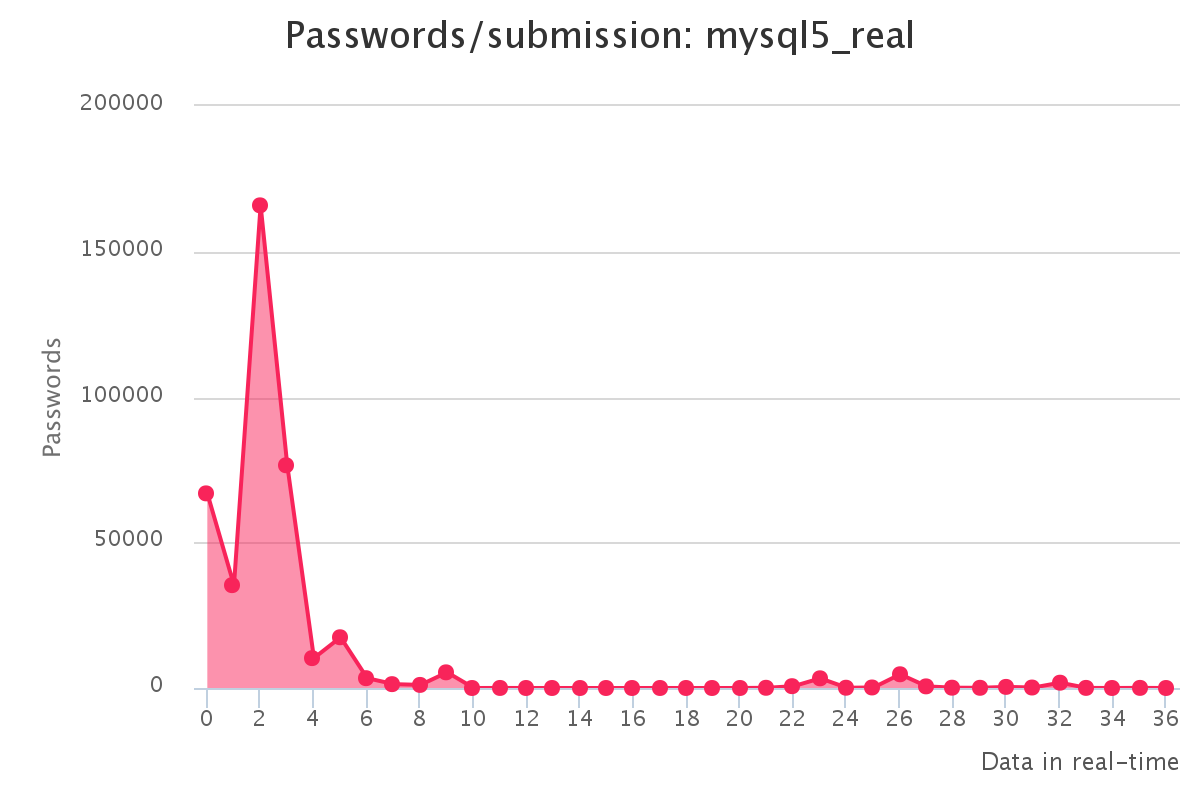
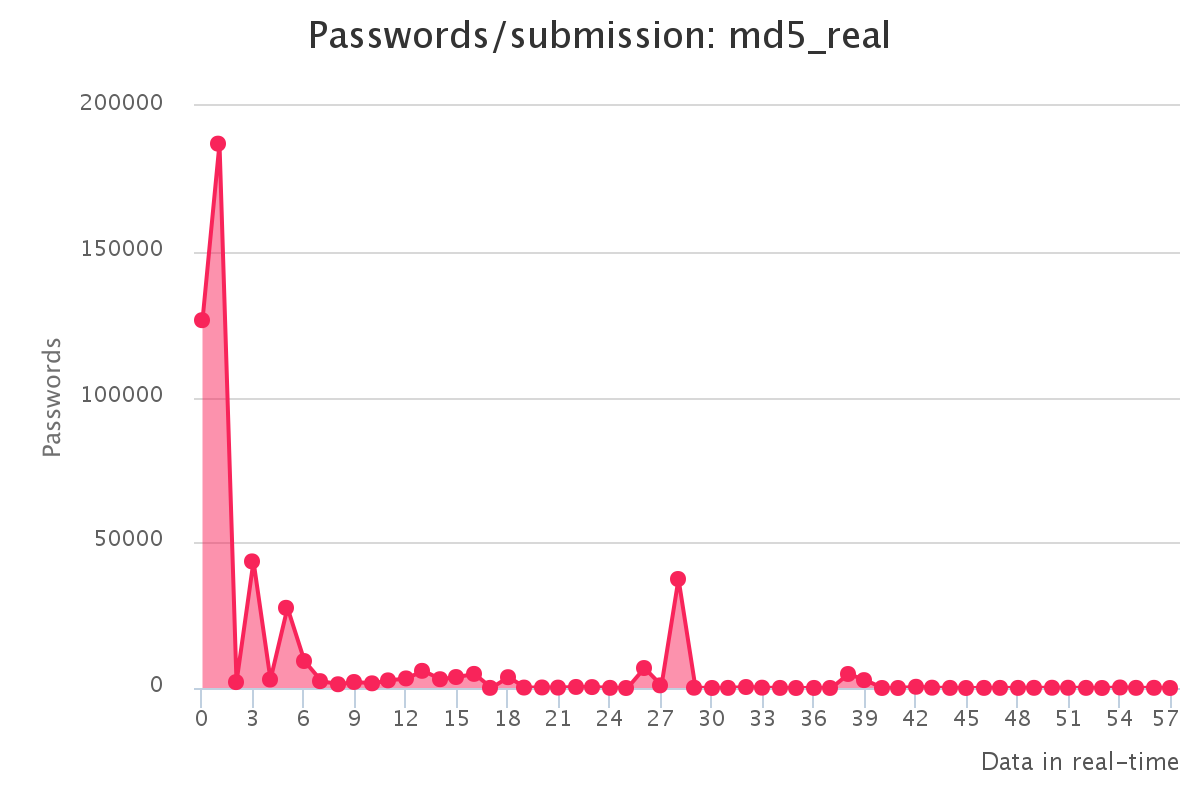
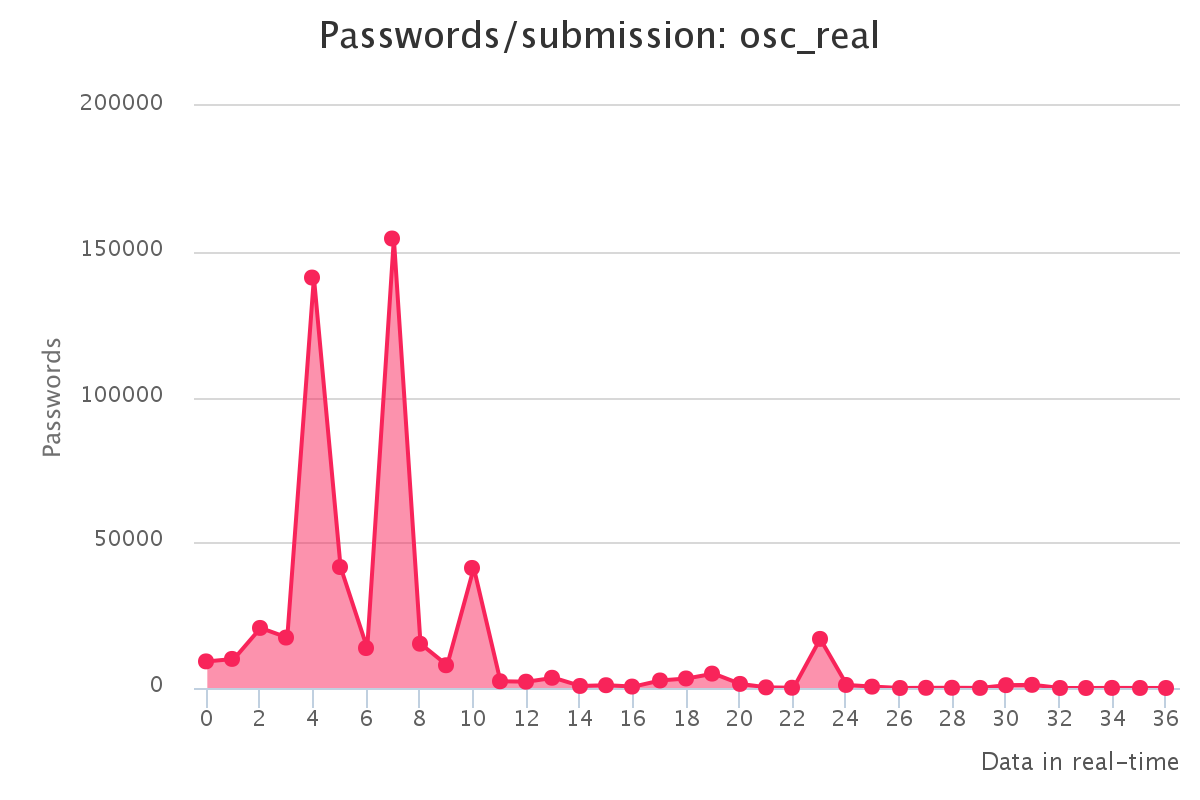
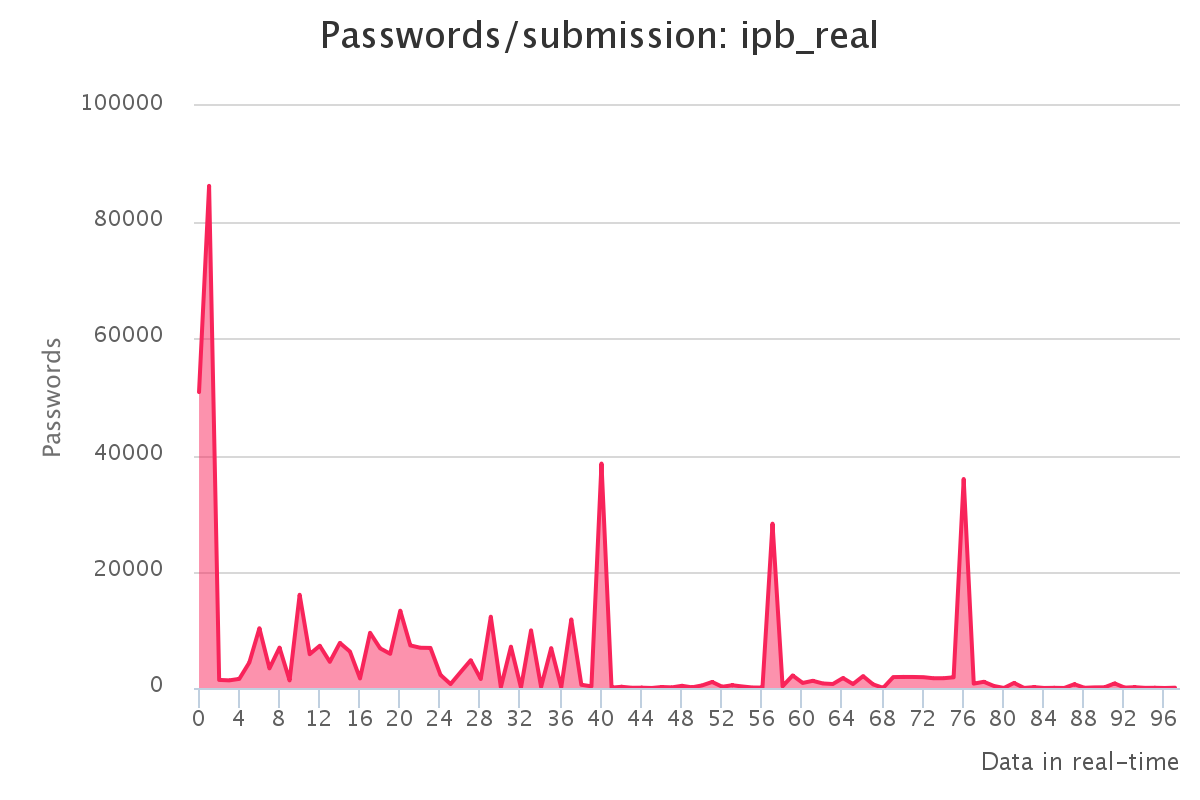
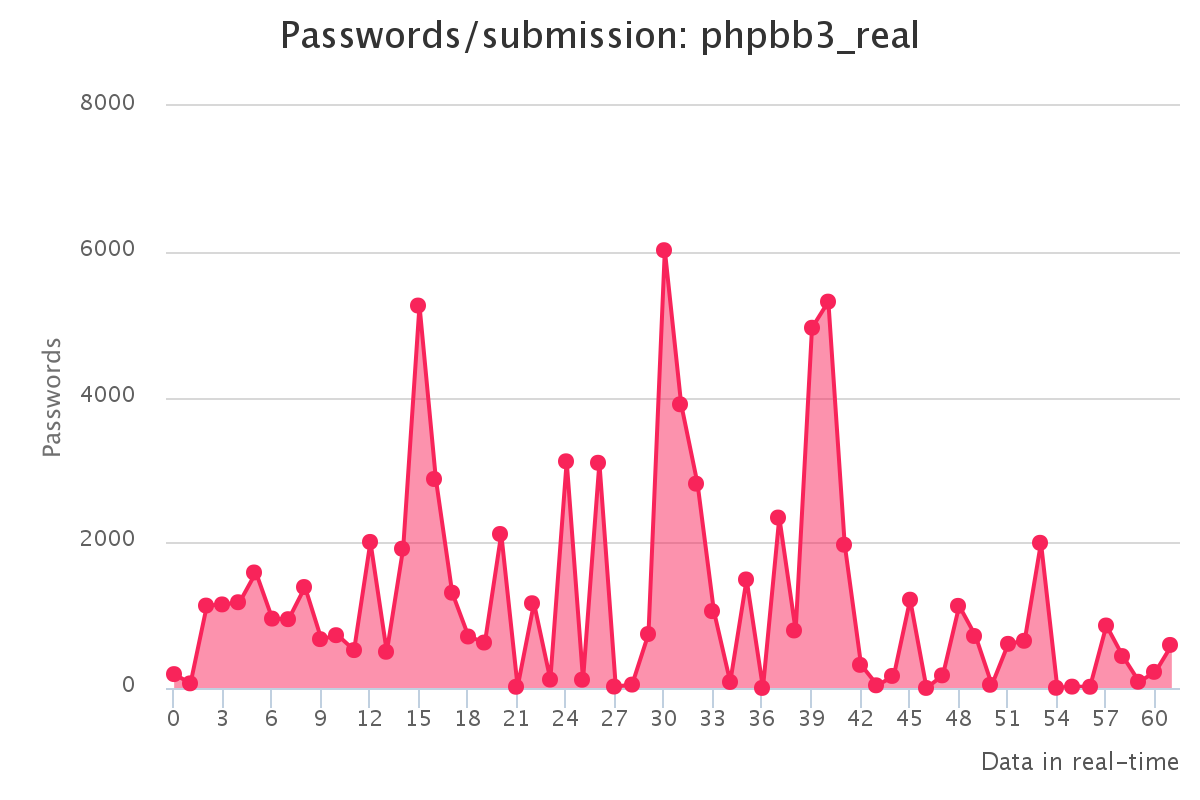
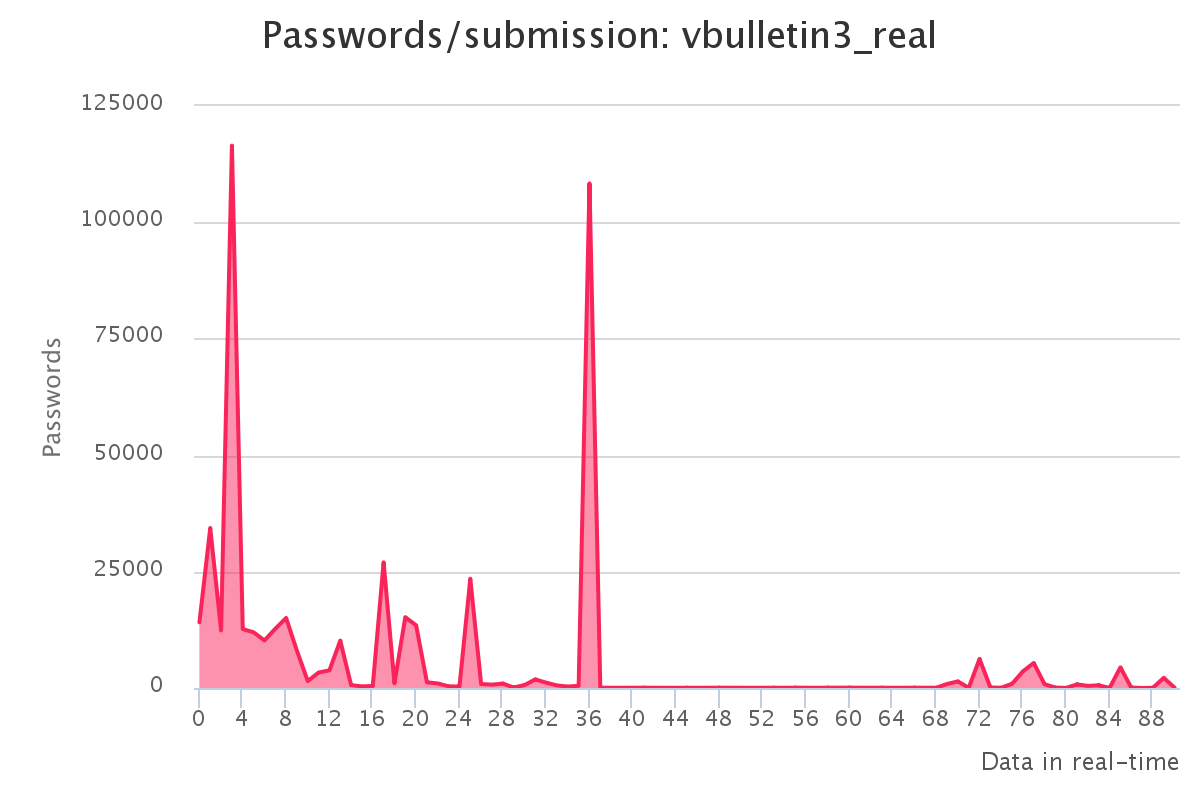
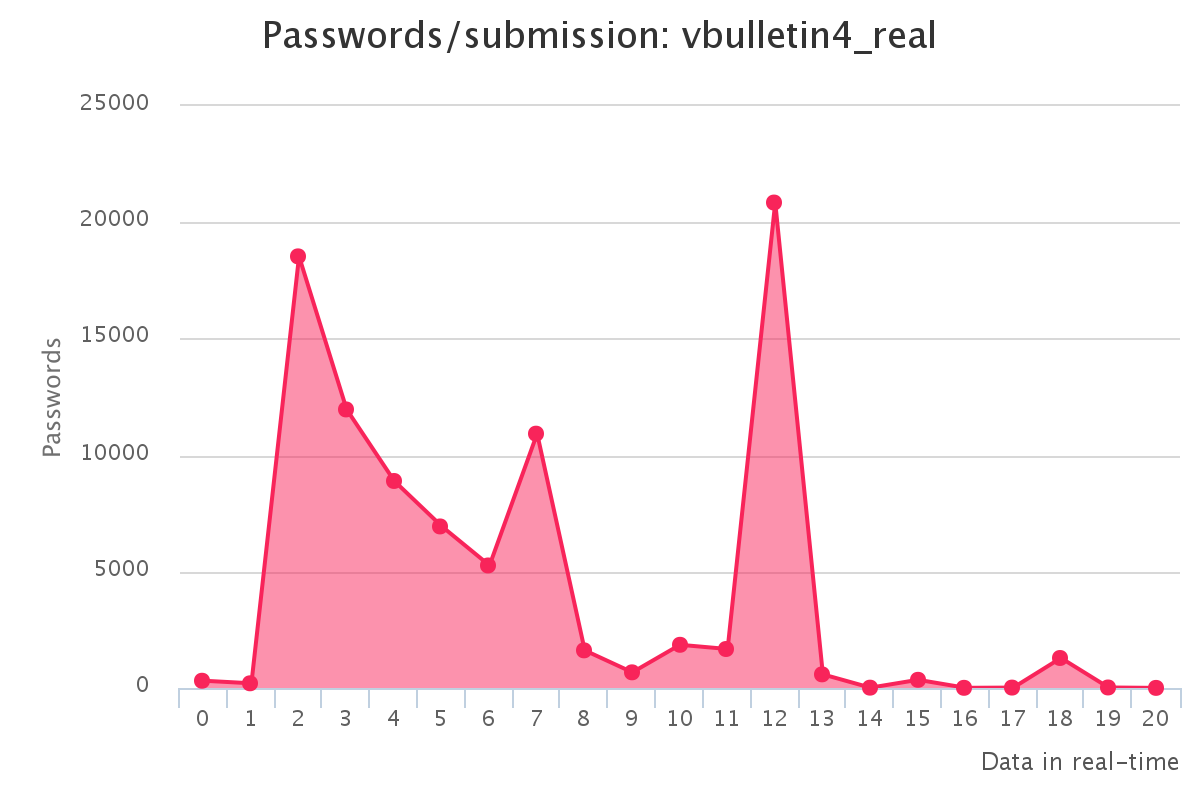

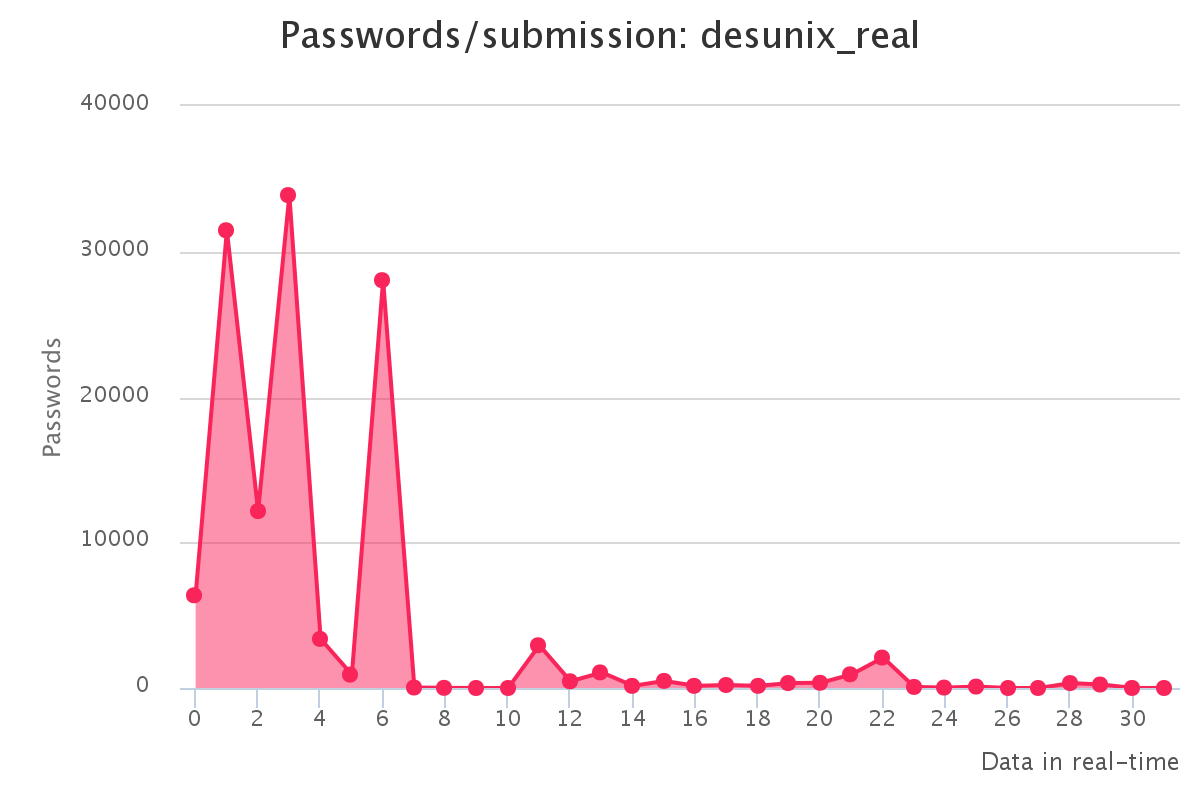
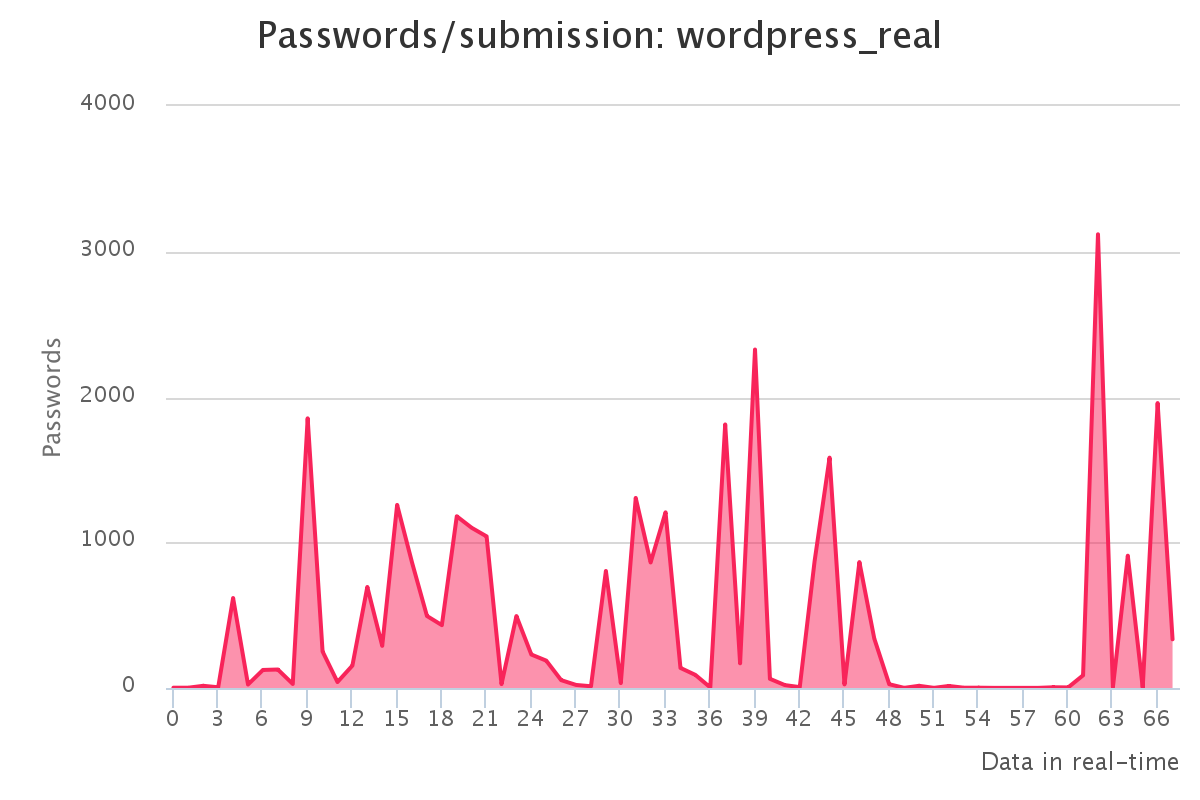
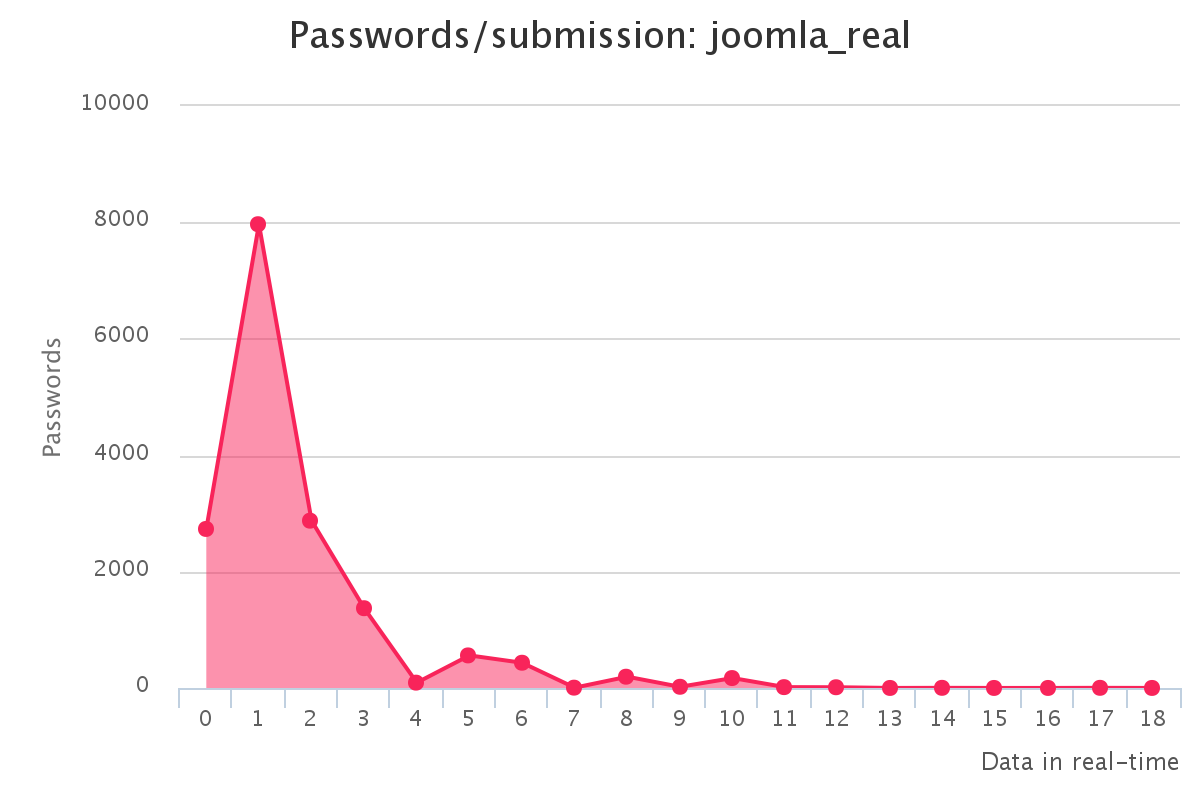
Graphs for generated hashlists

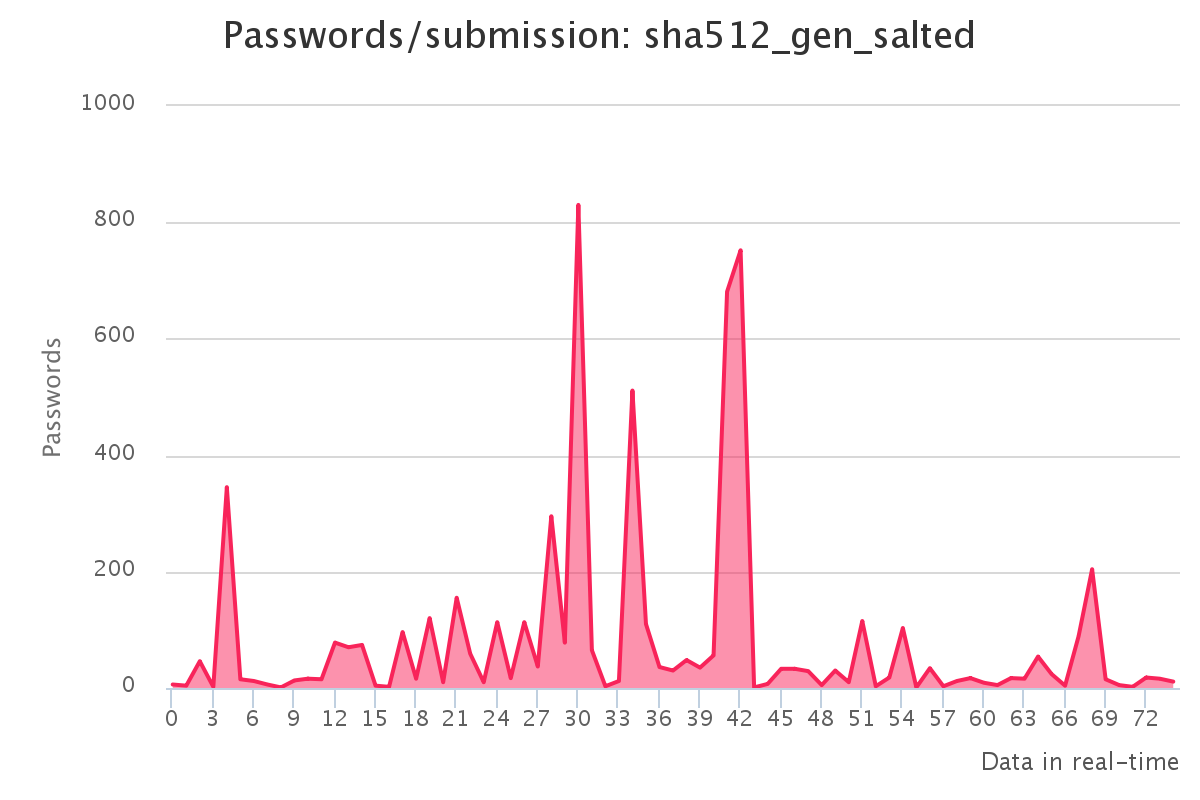
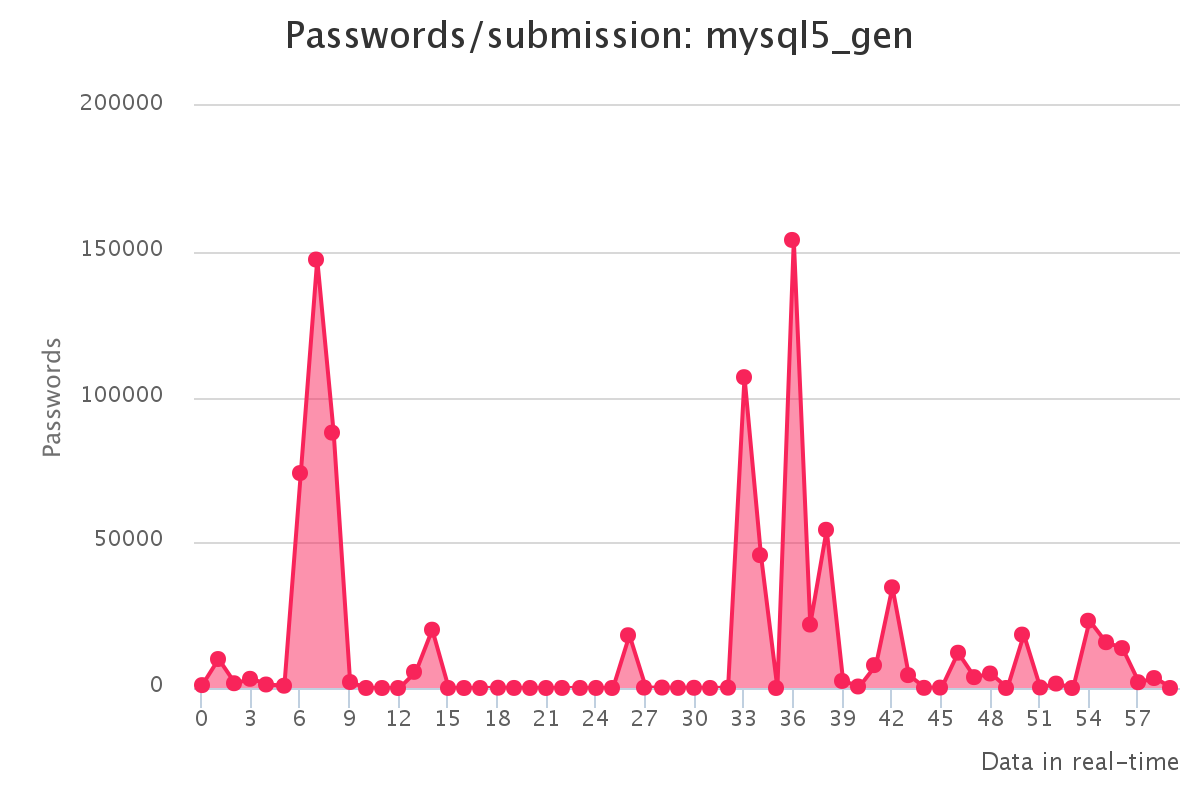
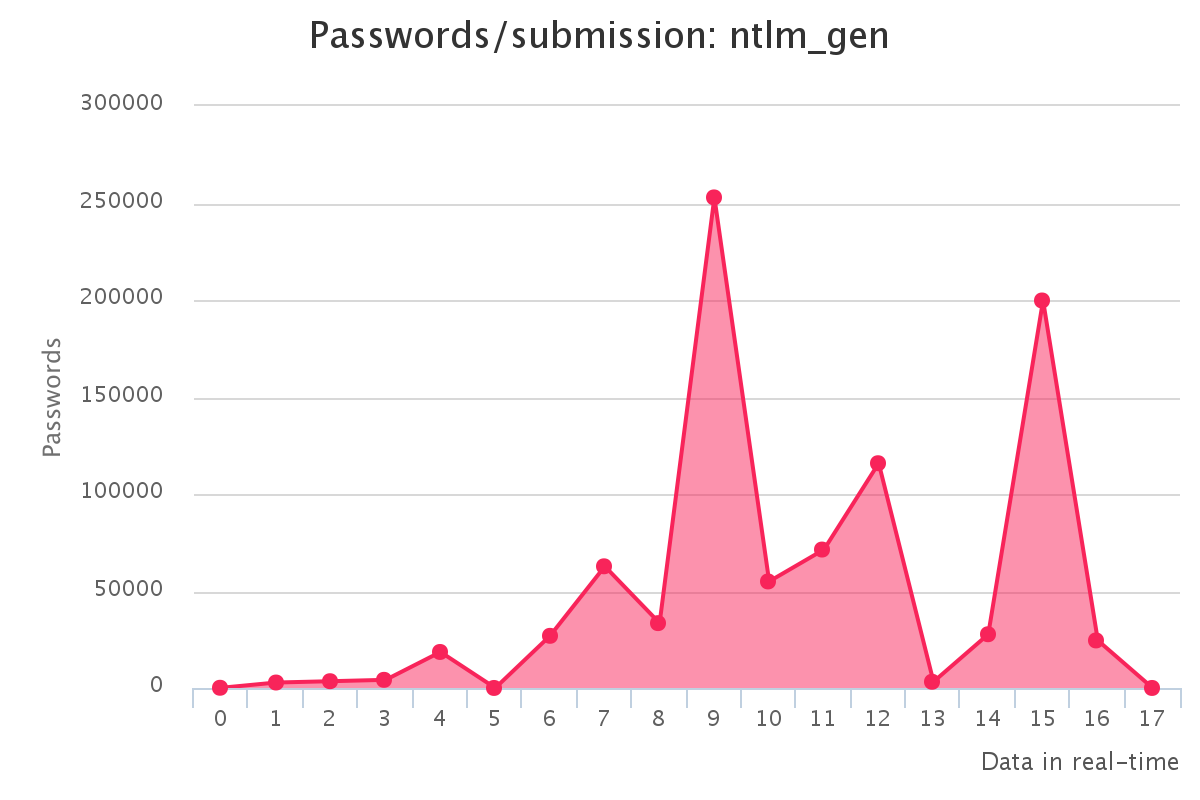
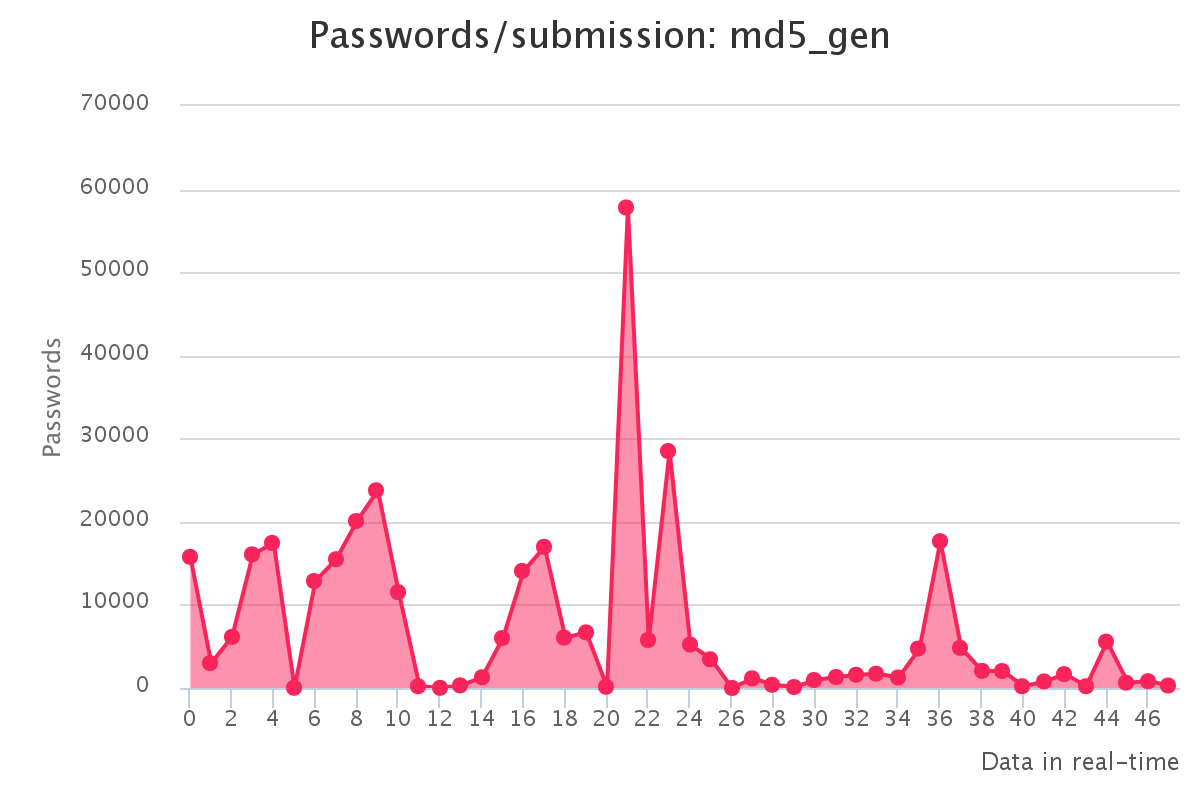
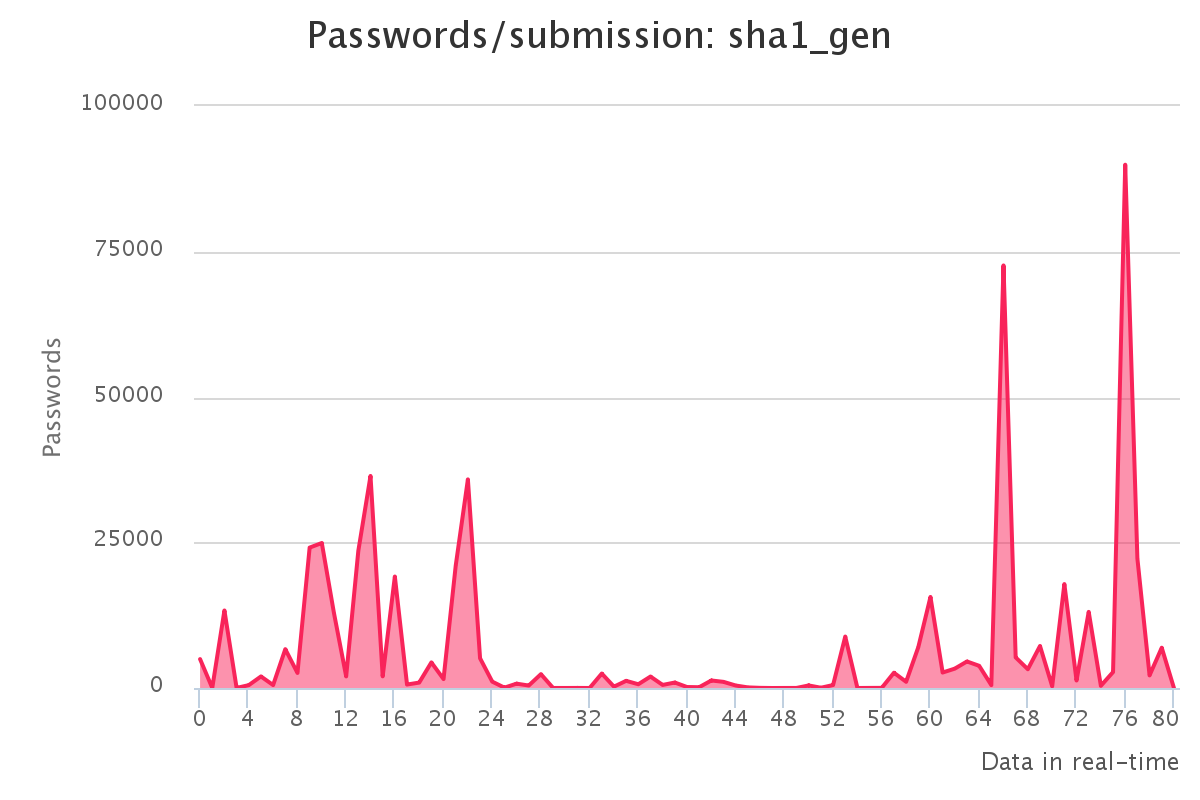
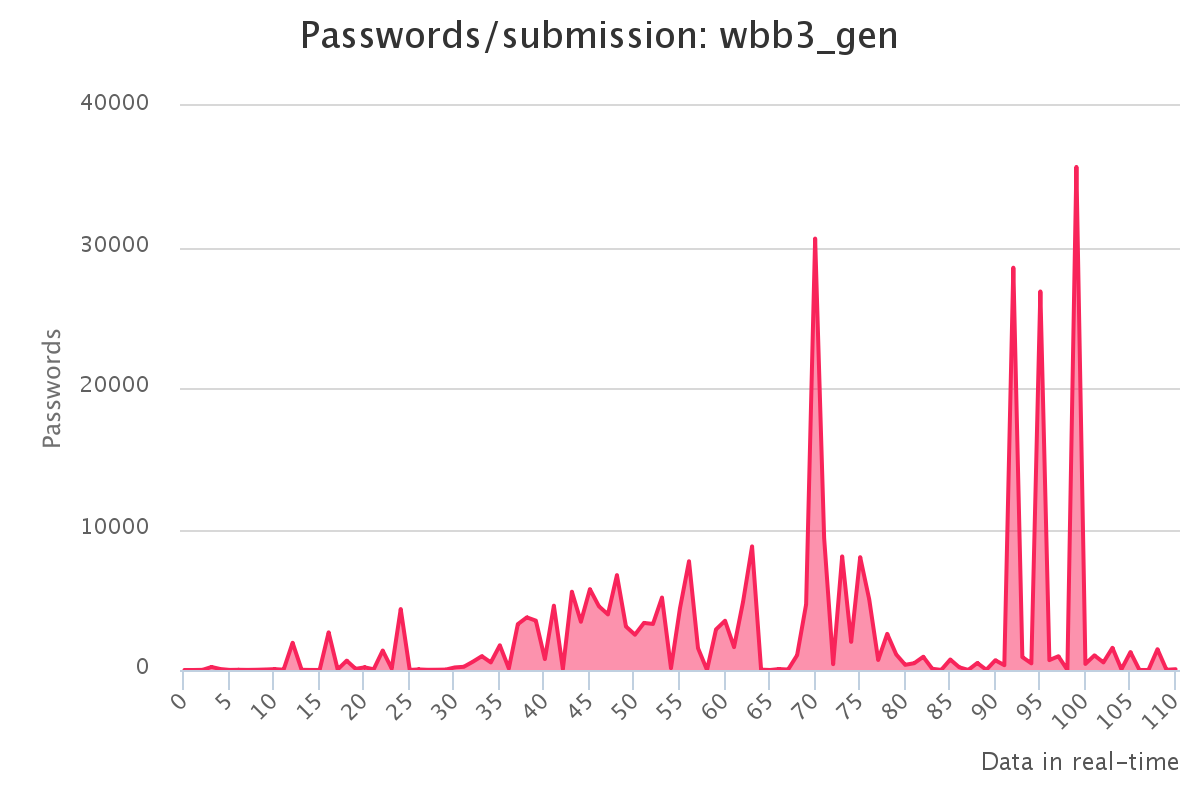
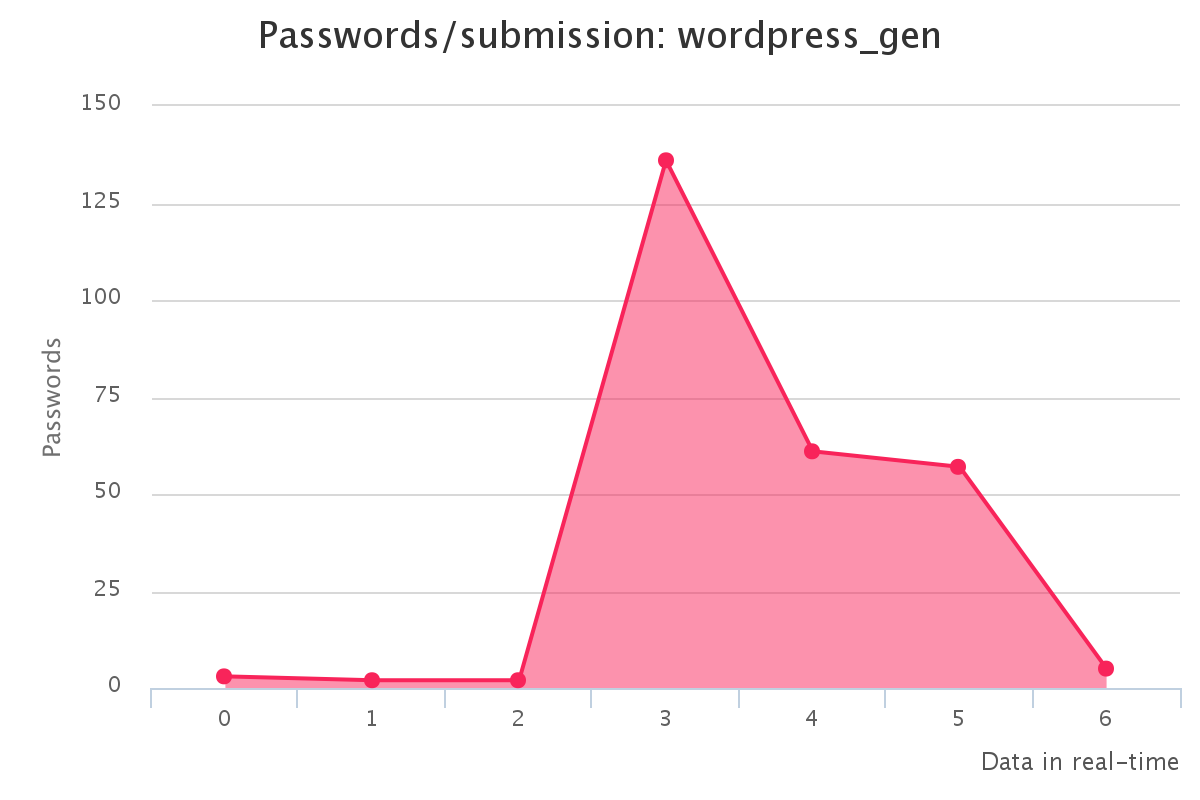
Interesting observations
As a portion of the hashes were from the real environment there is always the chance the hashes are mislabeled. We identified some DoubleMD5 labelled as MD5, these hashes tackled by cracking the initial MD5 list as DoubleMD5 then performing a single MD5 on the password prior to submission. We also identified vBulletin <3.8.5 hashes which were mislabeled MD5:pass with the salt being the plain for this MD5, there was no possible way to submit these since they were technically solved.
Once again since there were real world hashes, sometimes hashes become corrupted during extraction or transport. A feature of hashcat is that does not match every bit of the hash, allowing it to essentially detect a mistyped hash. We encountered a small portion of these which we assumed were most likely corrupted. As there wasn’t a large number of these, we simply ignored them.
While GPUs are extremely powerful in parallel hash cracking, it was surprising to see that the top scorer in our team predominately used CPUs.
Final remarks
A huge thanks to Bitcrack and Hashkiller for organizing an almost flawless contest, we had plenty of fun and very little sleep. We can only imagine the amount of time and effort put into arranging this contest to ensure it run so smoothly. Congratulations to Team Hashcat on their second place, glad we’re able to finally beat our rivals. Congratulations to the FCHC, I’m in your Wifi, LeakedSource and all other teams who participated.
